Key Features to Evaluate Multiple LLMs
Comprehensive feature set to meet your custom needs.
Custom Grading Parameters
Our LLM Evaluation Platform stands out with its powerful custom grading parameters feature. We understand that every task and prompt is unique, and evaluating model performance requires flexibility and precision. That’s why we let users define their own custom grading parameters tailored to their specific use case.
- Define Task-Specific Metrics
Whether it’s accuracy, relevance, creativity, factual correctness, or response tone, users can set the evaluation criteria that matter most to their application.
- Involve Experts and Models
Grading can be done manually by domain experts to ensure human-level oversight and understanding. Later, these parameters can also be evaluated by models for scalability and consistency.
- Create Multiple Parameters
Users aren’t limited to one evaluation metric — they can create and apply multiple parameters, providing a holistic assessment of model performance.

State of the art Table UI
Our LLM Evaluation Platform takes response analysis to the next level with a state-of-the-art Table UI for side-by-side comparison of LLM outputs. This highly interactive and customizable interface enables users to dive deep into model performance, spot differences, and make informed evaluations with ease.
- Compare Responses Side by Side
View multiple model responses next to each other for quick and clear comparison.
- Filter Results
Easily filter responses based on grading parameters, model performance, or specific criteria.
- Adjust Row Height
Customize the view by adjusting row height to accommodate longer responses or fit more on the screen
- Add More Models and Presets
Expand the comparison by adding more models or different LLM configurations to the results.
- Re-run Evaluations
Make changes and re-run the evaluation seamlessly without disrupting the existing view.
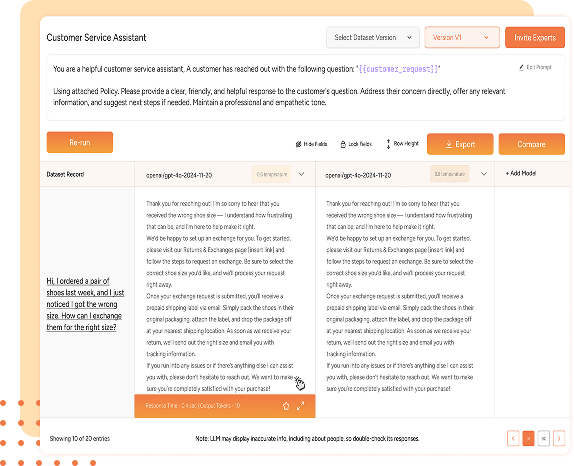
Expert and User Grading
Our LLM Evaluation Platform emphasizes the importance of human insight with its Expert and User Grading feature. This functionality allows teams to invite Subject Matter Experts (SMEs) to provide detailed evaluations, ensuring the most accurate and context-aware assessments of model responses.
- Invite Subject Matter Experts
Easily send email invitations to SMEs, granting them access to the platform for project evaluation.
- Grade on Custom Parameters
SMEs evaluate responses based on the custom grading parameters defined earlier, like accuracy, creativity, completeness, and more.
- Collaborate for Better Prompt Optimization
Expert input is crucial for refining prompts and optimizing model performance. SME feedback ensures model outputs align with real-world expectations and industry standards.
- Enhance Evaluation Quality
Combining user and expert evaluations provides a balanced, high-quality approach to grading, reducing bias and increasing result reliability.

Model based Evaluation
Our LLM Evaluation Platform introduces a groundbreaking Model-Based Evaluation feature powered by our proprietary Jury LLM. This feature enables users to scale Subject Matter Expert (SME) grading from small sample sets to large datasets, ensuring consistent and efficient evaluation without sacrificing quality.
- Scale Expert Insights
The Jury LLM learns from SME evaluations and applies the same judgment criteria to rate large volumes of model responses.
- Maintain Consistency
By modeling expert-level grading, the Jury LLM ensures uniform evaluation across an entire dataset.
- Save Time and Effort
Reduce the need for ongoing manual grading by automating evaluations with high accuracy and reliability.
- Refine Model Performance
Identify patterns and optimize prompts based on large-scale, expert-informed assessments.

Comprehensive Metrics
Our LLM Evaluation Platform offers a powerful and detailed Comprehensive Metrics Dashboard, giving users deep insights into model performance and evaluation results. This feature captures a wide array of metrics, enabling data-driven decisions and thorough performance analysis.
- Model-Level Performance Metrics
Total Latency: Measure end-to-end response time. Inter-Token Latency: Analyze the time taken between token generations.
Token Usage: Track total and average tokens consumed per response.
Throughput: Evaluate the number of requests processed within a given time.
Cost Analysis: Monitor API usage costs for better budget management.
- Moderation Metrics
Harmfulness: Detect potentially harmful content.
Toxicity: Measure the likelihood of offensive or inappropriate language.
- Accuracy Metrics
Custom Grading Parameters: See detailed scores on expert-defined evaluation criteria like accuracy, completeness, tone, and relevance.
- Flexible View Options
Model-Level Metrics: Compare different LLMs’ performance side by side.Provider-Level Metrics: Assess metrics across different model providers like OpenAI, Anthropic, and others.

Dataset Management
Our LLM Evaluation Platform provides robust Dataset Management capabilities, ensuring users have the right data to drive meaningful and statistically significant evaluations. This feature offers flexibility in handling datasets at both the project level and across multiple projects, supporting versioning and iterative improvements.
- Add Datasets at Project Level
Easily upload and associate datasets with specific projects for focused evaluation.
- View Across Projects
Access and manage datasets across multiple projects for broader analysis and insights.
- Update and Version Datasets
Create new versions of datasets, update them over time, and maintain a clear version history.
- Enable Statistical Significance
Use larger, well-maintained datasets to ensure evaluations reflect consistent and reliable model performance.
- Re-run Evaluations
As datasets evolve, seamlessly re-run evaluations on updated versions without disrupting workflows.
