User-Centric Evaluations
Designed with end-users in mind, our platform provides nuanced insights that go beyond traditional metrics.

Subject Matter Expert Review
Leverage detailed assessments from industry experts with deep domain knowledge and technical expertise.

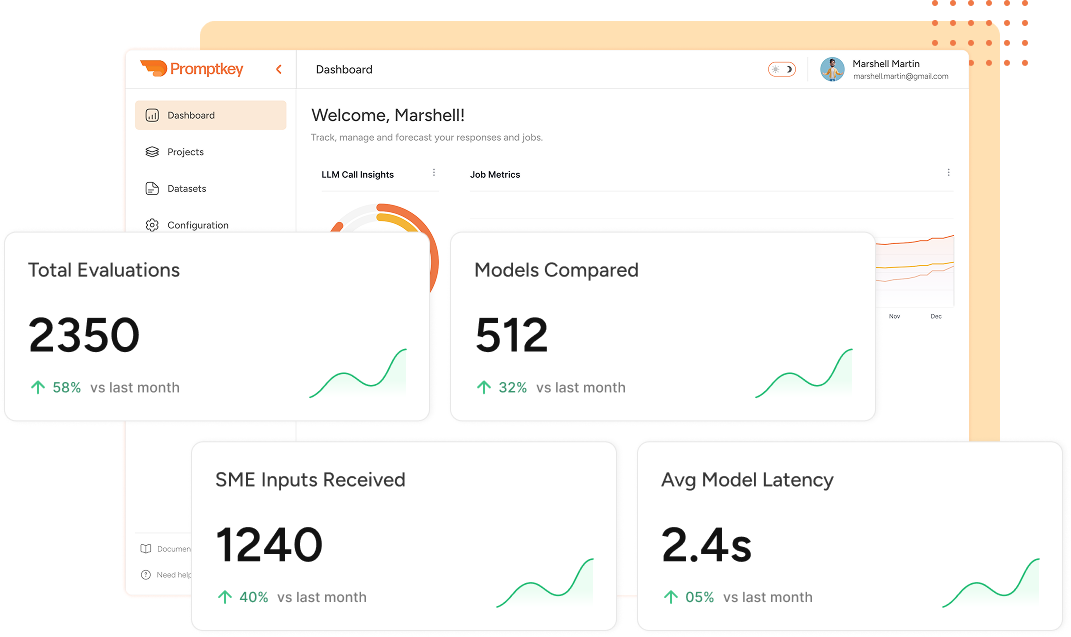
Moderation Dashboard
Gain real-time AI performance insights with our intuitive moderation dashboard. Track key metrics, monitor outputs, and ensure quality, compliance, and consistency.






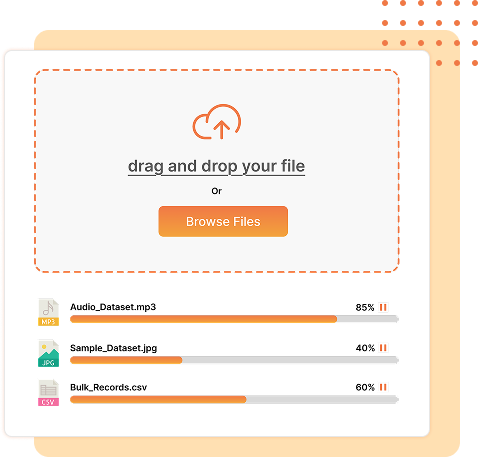
Manage & Generate Your Datasets
Organize, curate, and generate high-quality datasets tailored to your evaluation needs. Effortlessly version datasets to track performance over time.
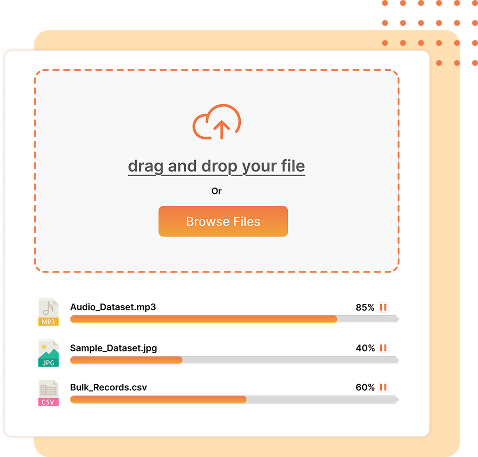
Manage & Generate Your Datasets
Organize, curate, and generate high-quality datasets tailored to your evaluation needs. Effortlessly version datasets to track performance over time.

Create Powerful Prompts Connected to Your Data
Design effective prompts that seamlessly integrate with your datasets, ensuring context-rich evaluations for consistent model performance.
Create Powerful Prompts Connected to Your Data
Design effective prompts that seamlessly integrate with your datasets, ensuring context-rich evaluations for consistent model performance.


Connect Multiple LLM with Flexible Configurations
Integrate multiple LLMs with ease. Experiment using various presets, fine-tuning parameters like temperature, output tokens, Top P, and frequency penalty—all in one interface.
Connect Multiple LLM with Flexible Configurations
Integrate multiple LLMs with ease. Experiment using various presets, fine-tuning parameters like temperature, output tokens, Top P, and frequency penalty—all in one interface.


Evaluate LLM Responses with SMEs
Leverage SME insights to assess model outputs accurately. Collaborate, score, and analyze responses to ensure data-driven evaluation at scale.
Evaluate LLM Responses with SMEs
Leverage SME insights to assess model outputs accurately. Collaborate, score, and analyze responses to ensure data-driven evaluation at scale.